
Sopa genera y publica contenido automáticamente para que tu empresa gane visibilidad y consiga leads sin depender de agencias ni dedicar tiempo a marketing.
La mayoría de empresas saben que necesitan generar contenido para aparecer en Google, redes sociales y en herramientas como ChatGPT.

Crear contenido llevan mucho tiempo. Los equipos de marketing dedican horas a escribir posts, artículos y contenido para redes.

Cada canal funciona diferente. Google, redes sociales y LLMs requieren estrategias distintas.

Las herramientas están fragmentadas. Las herramienta de SEO, las de RRSS y generadores de contenido no trabajan juntos.

Las empresas no saben cómo aparecer en respuestas de IA. Cada vez más personas buscan información directamente en:
Sopa analiza qué buscan tus clientes, genera contenido optimizado y lo distribuye automáticamente en todos los canales relevantes.
La mayoría de empresas saben que necesitan generar contenido para aparecer en Google, redes sociales y en herramientas como ChatGPT.
Sopa analiza tu web y detecta qué buscan tus potenciales clientes en Google, redes sociales y asistentes de IA.
Creamos contenido estratégico optimizado para posicionarse en buscadores, redes sociales y motores de respuesta como ChatGPT.
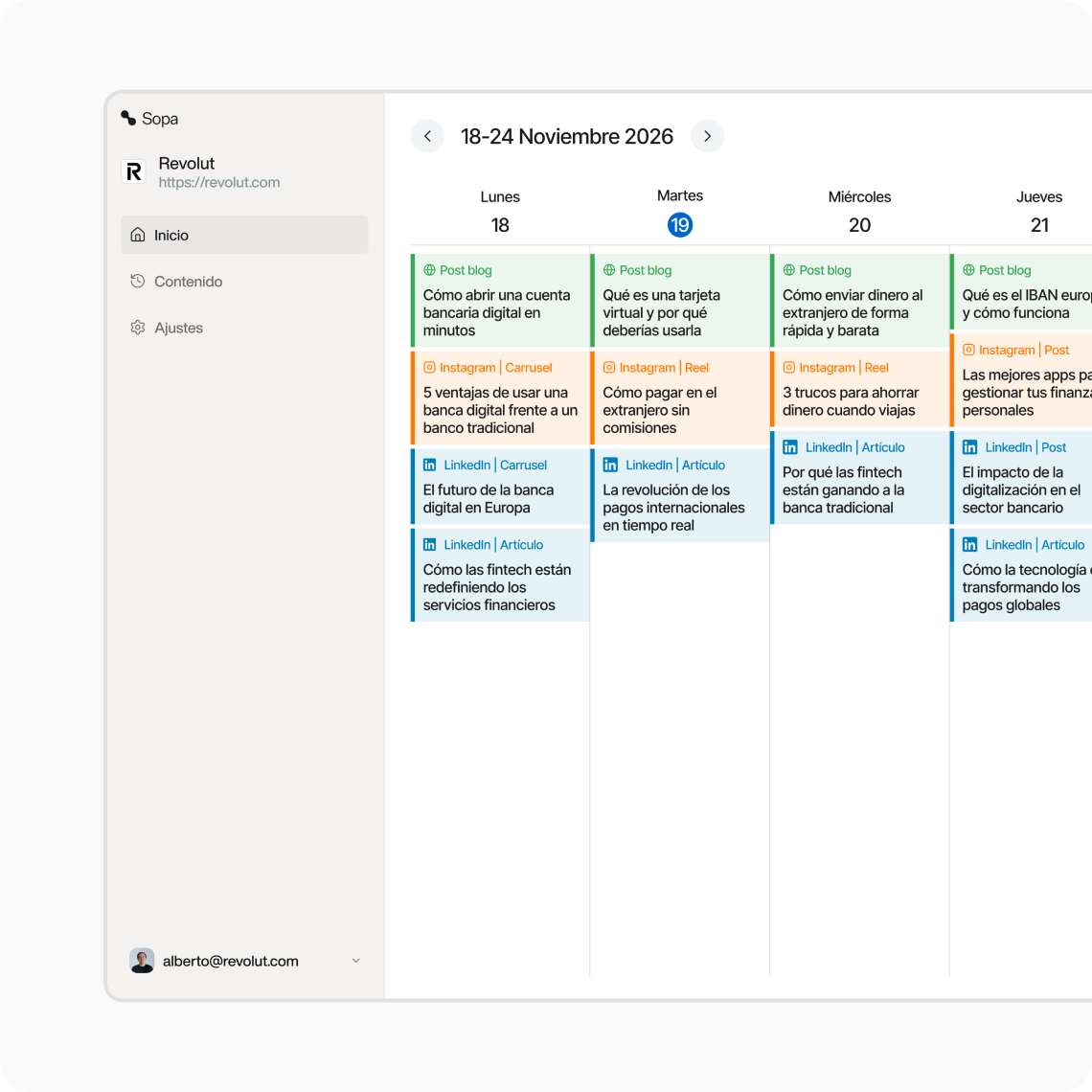
Sopa publica contenido diariamente en distintos canales para aumentar tu visibilidad y generar demanda de forma constante.
Mientras tanto, otras empresas están generando visibilidad todos los días.
Y ganando los leads.
Sopa genera y publica contenido automaticamente en los canales donde tus clientes buscan información.

Contenido que genera visibilidad profesional y atrae clientes B2B.

Creamos contenido estratégico para posicionarse en buscadores, redes sociales y motores de respuesta como ChatGPT.

Reels y publicaciones para ampliar el alcance de tu marca.

Contenido pensado para ganar visibilidad en formatos de vídeo.

Contenido pensado para ganar visibilidad en formatos de vídeos corto.
Hoy las personas no solo buscan en Google.
Si no apareces aquí, no existes.
Sopa se encarga de generar contenido para posicionarte en todos ellos.


Tu empresa aparece cuando los clientes buscan soluciones.

Más presencia significa más oportunidades comerciales.

Sopa se encarga de crear y publicar el contenido.

Reduce hasta un 90% el coste frente a agencias tradicionales.
Costes elevados
Procesos lentos
Dependencia de equipo externo
Poca frecuencia de contenido
Mucha coordinación
Hasta 90% más barato
Publicación continua
Automatización
Contenido diario
Todo automático
Todo se publica automáticamente.
El tiempo es dinero. Ahorra ambos